Improving UI Design with a Generator–Evaluator Loop
Good UI design is still hard.
LLMsLLMLarge Language Model — a neural network trained on vast text data to understand and generate human-like text. have made it easier to generate designs quickly but most outputs look the same. Without direction, you end up with generic layouts that resemble hundreds of AI-generated sites.
Earlier, designs would default to purple or dark themes without any prompting. With this experiment, the UIUIUser Interface — the visual layer through which a user interacts with software. now goes beyond the standard LLMLLMLarge Language Model — a neural network trained on vast text data to understand and generate human-like text. baseline.
Experiment
Goal
Design a personal blog UIUIUser Interface — the visual layer through which a user interacts with software..
Approach
Create a feedback loop using two agentsagentAn autonomous AI system that plans and executes multi-step tasks, often using tools and feedback loops.:
- Generator agentagentAn autonomous AI system that plans and executes multi-step tasks, often using tools and feedback loops. → produces design ideas and iterations.
- Evaluator agentagentAn autonomous AI system that plans and executes multi-step tasks, often using tools and feedback loops. → scores designs based on defined criteria
Both agents can use a web search for inspiration.
Scoring Criteria
Each design is evaluated on:
- Originality
- Simplicity
- Aesthetics
- Use of CRAPCRAPDesign principles: Contrast, Repetition, Alignment, Proximity — a framework for evaluating visual layout quality. principles (Contrast, Repetition, Alignment, Proximity)
- Non-AI generated
- Innovation
- Creativity
Target: Score ≥ 9
Constraint: Prefer simple solutions over complex ones, unless complexity is necessary.
LLM Prompt
Can we create a generator and evaluator agent loop to create a blog design and iterate? The generator comes up with a design and evaluator scores to improve on these metrics...originality, simplicity, aesthetics, valuable, CRAP rules,innovative, creative, and non-ai-generated scores till we reach a score of 9Results
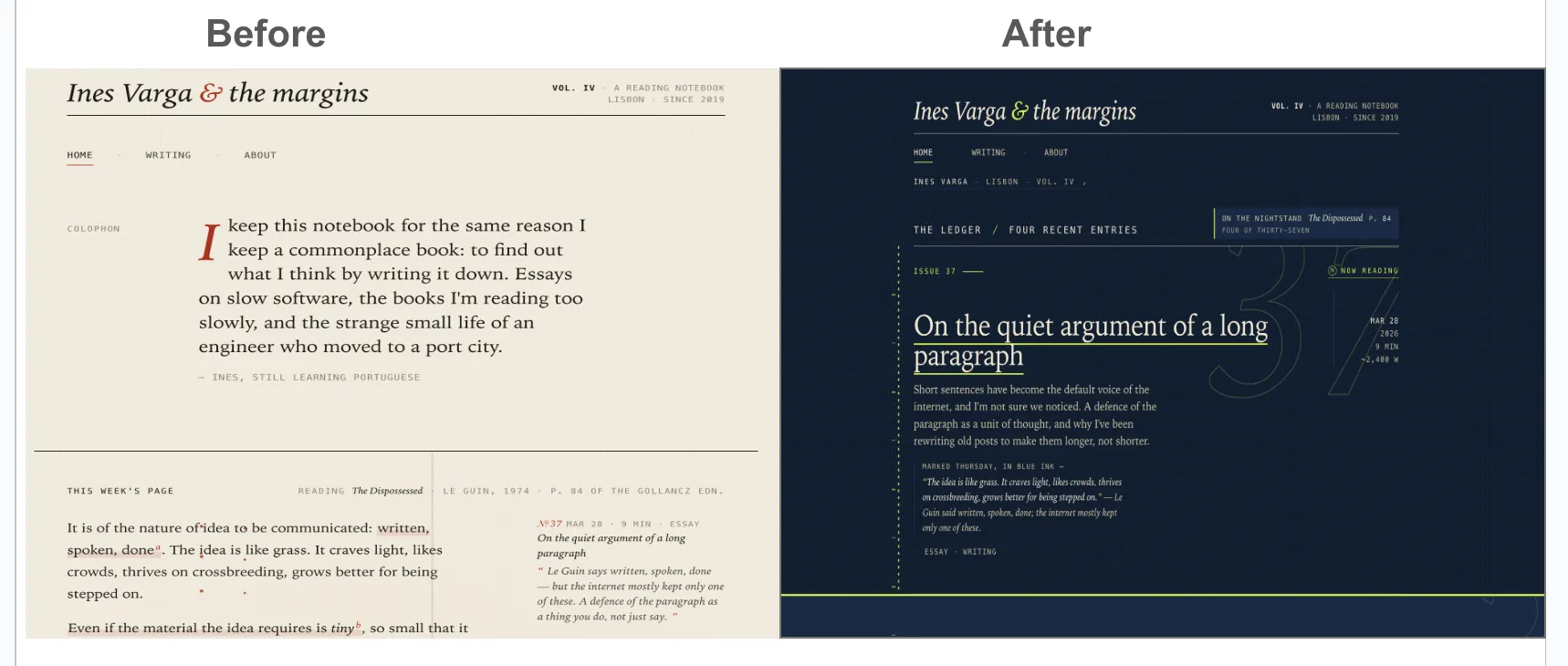
Model: Sonnet
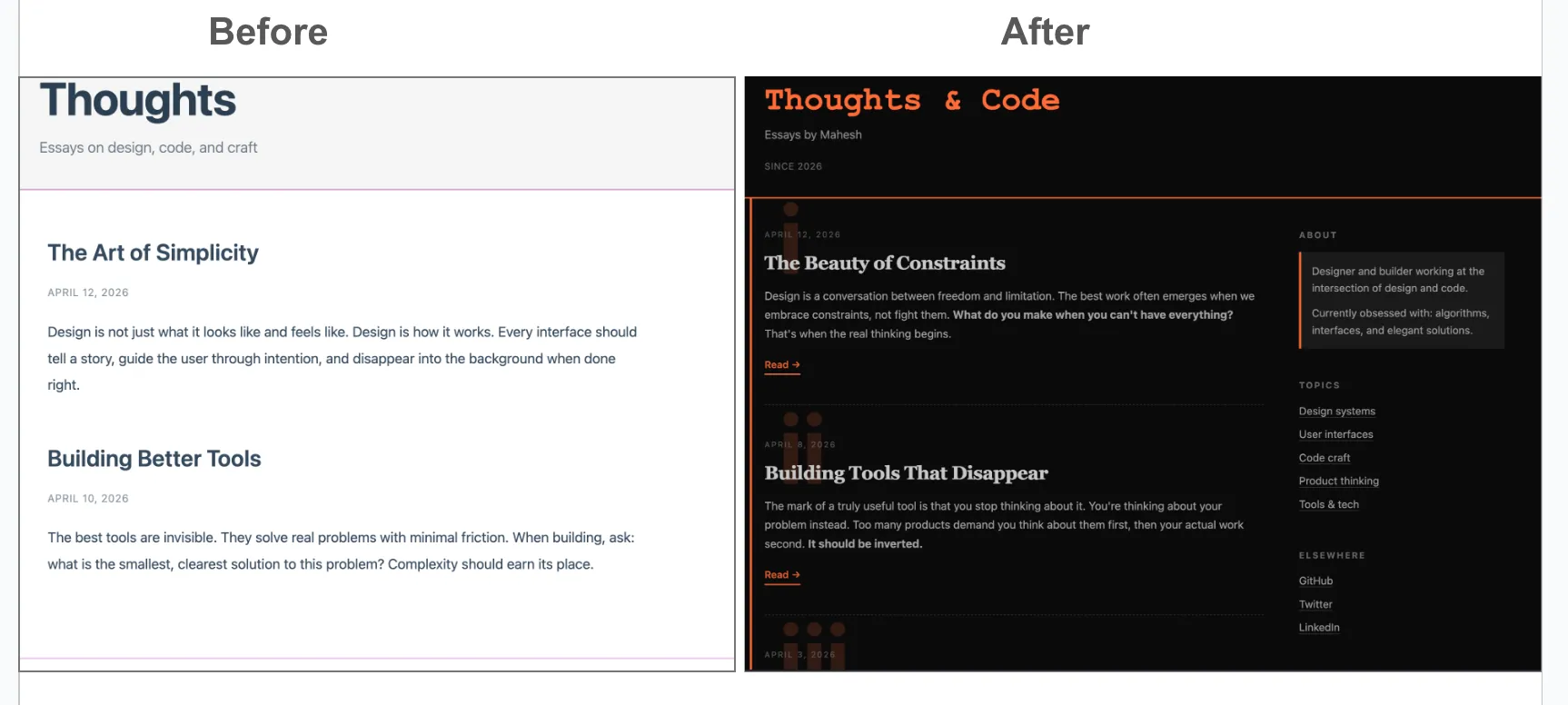
Model: Haiku
Evaluator sample scoring screen
FINAL SCORES (Iteration 11)
──────────────────────────────────────────────────────────
originality │ 8/10 — Margin-line metaphor, 3-register type system
simplicity │ 8/10 — Orange system coherent, clean hierarchy
aesthetics │ 8/10 — Asymmetric grid 680/280 creates spatial tension
valuable │ 8/10 — Clear scannability, sparse sidebar
crap │ 8/10 — All 4 CRAP principles operating coherently
non_ai │ 8/10 — 680/280 specificity, deliberate design intent
creative │ 8/10 — Ghost numerals + type contrast + asymmetry
innovative │ 9/10 — Bold structural layout breaks conventions
──────────────────────────────────────────────────────────
JOURNEY: 0→11 iterations
─────────────────────────────────────────────────────────
Iter 0: Generic blog template (avg 5.9/10)
Iter 1: Added constraint metaphor (avg 6.4/10)
Iter 2: Bold black + orange + monospace (avg 7.0/10)
Iter 3: Collapsed margin, intentional spacing (avg 7.1/10)
Iter 4: Added marginalia annotations (avg 7.4/10)
Iter 5: Refined to scholarly minimalism (avg 7.9/10)
Iter 6: Micro-refinements (plateau) (avg 7.6/10)
Iter 7: System sans-serif body (breakthrough) (avg 7.9/10)
Iter 8: Ghost numerals (hedged commit) (avg 7.6/10)
Iter 9: Bolder numerals + Georgia serif (avg 7.9/10)
Iter 10: Fixed CRAP (all 8/10) (avg 8.0/10)
Iter 11: Asymmetric grid 680/280 (complete) (avg 8.1/10)
Learnings
- Metrics drive quality : A strong model alone isn’t enough. Clear scoring criteria significantly improve outcomes.
- Direction matters more than raw capability : Even average models perform better when guided with structured evaluation.
- Evaluator > self-critique : Separate evaluator agentsagentAn autonomous AI system that plans and executes multi-step tasks, often using tools and feedback loops. outperform self-evaluation by the generator.
- Initial vision helps: Providing a clear starting direction improves both convergence speed and output quality. This also enhanced the styling of this blog post.
- Model differences are real.
- Sonnet: best balance of cost, speed, and quality
- Haiku: fast but weaker design sense
- Opus: strong, but not significantly better than Sonnet for this use case
Next Steps
- Refine scoring criteria to push designs further away from generic patterns.
- Introduce reference designs to guide exploration.
- Test additional models (Gemini, Codex)
- Experiment with multi-model combinations (e.g., one generates, another evaluates)
Closing Thoughts
This pattern isn’t new. It mirrors human workflows like design reviews and code reviews. What’s new is the scale at which agentsagentAn autonomous AI system that plans and executes multi-step tasks, often using tools and feedback loops. can automate these patterns in places we might not have anticipated earlier with humans.
With clear goals, metrics, and iteration loops, agents can:
- Raise the baseline quality of design.
- Help non-designers produce strong outputs.
- Accelerate exploration in unfamiliar domains.
This feels like an early version of a broader shift: structured iteration + autonomous agents → better outcomes across domains.
References
- Anthropic engineering post : https://www.anthropic.com/engineering/harness-design-long-running-apps
- Had versions of this earlier, but never formalized. This post gave words to formalize this approach and try this experiment.
- AutoResearch (related idea: vision + metrics + iteration) : https://github.com/karpathy/autoresearch
- Though not related, but very much in line with this pattern of vision + metrics with agent autonomy.
- Design principles : https://www.lewisu.edu/writingcenter/pdf/crapdesignprinciples.pdf
- Claude models : https://platform.claude.com/docs/en/about-claude/models/overview#latest-models-comparison